全文検索導入で失敗しない!

全文検索システムはなんでも見つけられそうで、実はなかなか見つけられない。それが何故なのか、どうしたら解決できるのか考えてみます。
全文検索システム導入での失敗
紙文書を電子化する場合には、OCR(Optical character recognition)機能で透明テキスト付きPDFを作成することをお勧めしています。なぜなら、電子の状態で生まれてくる電子文書と同様に書いてある文字を使ってテキスト検索が可能になり利便性をあげることができるからです。
つまり、全文検索できるようになります。
しかし、これだけでは文書が多いとヒットしすぎて、文書が見つけにくいとか結局探せないとか
必要なデータにたどりつけない
ということが起こりがちです。
「再現率」は高い、「適合率」は低い
実は、全文検索はデモ効果がとても高いです。OCR処理したPDFなどを作成してお客様に見ていただくと、キーワードが文書中に反転していてわかりやすく表示されます。文中の単語が一目瞭然!!すごく便利です。 こんなに便利に見えたのに、なぜ「必要なデータにたどりつけない」ことが起こるのでしょうか。
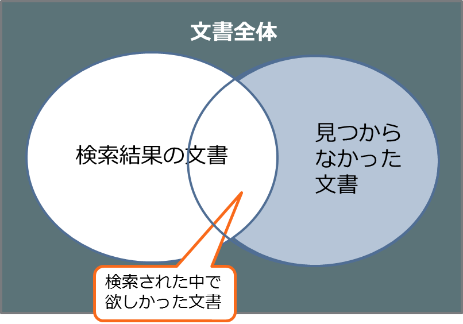
①よく見えるのは「再現率」が高いから。 文書の中にある文字が全て検索対象になることから、メタデータだけの検索よりも多くの検索結果を検出できます。その結果、あっても見つけられないという懸念からは開放されます。
なんでも見つかりそうな気がします。
②たくさんあり過ぎてその選別に苦労する。「適合率」が低い
逆に見つかり過ぎます。メタデータの項目の1つであるキーワードはその文書を代表とするテーマから付与しますが、全文検索は全ての文字列が対象となりますので、その文書のテーマ以外でも表現のために使われた文字列は検索対象となってしまいます。したがって、検索ノイズが出てしまいます。
③データが少ないうちは気づきにくい。 デモなどで見る時は、少ないデータで行うことが多いです。また、全文検索では1つの文書を例にしてご覧いただくことばかりなので、検索テーマに適合しているかの選別の過程を検討することがないので気づきにくいです。
インターネットと社内システムでの情報検索
インターネット検索エンジンのGoogle はインターネット全体を検索対象としますが、ユーザーファーストの方針によって、上位表示はGoogle のフィルタにかけられて表示されます。利用者側もそれをよく知った上で利用します。
情報の海からピックアップ
する感覚です。
一方、社内の文書を探すときはどうでしょう。
根性で何が何でも探し出し
ますよね。なぜなら、絶対あるのはわかっている、なければ最初から作りなおさければならない。なので、何が何でも探し出す。ことになります。 全文検索で候補がたくさん見つかって、どれだかを選別するのに時間がかかってしまうこともよくあります。
全文検索有効利用のための方策
全文検索システムを導入したけれどもうまく活用されていないという話は聞きますが、ないほうがいいとか人間の目で探した方がいいとかそういう人はいないと思います。やっぱり、使うべきところにコンピュータを使った方がいいということだと思います。 では、有効利用をするためにはどうしたらいいのでしょうか。ここでは2つのデータ管理を考えてみます。
①データの階層(グループ)化の有効性 データを階層化して整理し、全文検索はその範囲内で行い、後に来る選別の手間を縮小します。 おおざっぱでもある程度小分けの箱に入れて、その中を探す感覚です。
②タグ付けの有効性 階層化は、データの配置を示すため、1つの文書は1つの箱にしか入れられません。複合的に主題を表すためにタグも付与しておきます。タグは文字利用の揺れをなくすために登録制にしておくとよいでしょう。 (コンピュータを表すのに「コンピュータ」と付与する人と「電子計算機」と付与する人がいたらうまく探せません。)
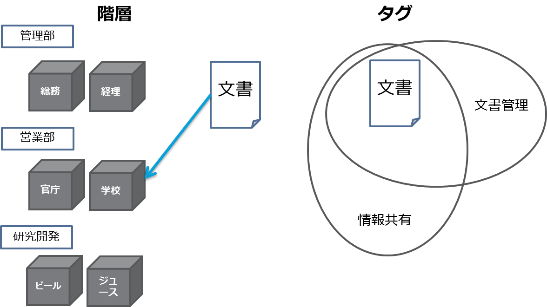
階層は、予め入れる箱を用意して、文書を片付けていくイメージです。タグは、ひとつの文書にいくつでも付与できます。
なんでも同じ袋の中に雑多に入れて「はい、探しましょう!」では、なかなかうまくいきません。
情報が多くなればなるほど、検索の精度を高める工夫は必要となります。
コンサルティング事業部/石川
ニュース・お知らせ

文書管理でお悩みの方は、お気軽にご相談ください
お問い合わせください
こちらから
組織の知カラとは?
文書管理の専門家が長年培ってきたノウハウを企業担当者に向けて配信するサイトです。
お役立ち資料
【AI時代のデータマネジメント新常識】 ナレッジマネジメントを成功へ導く、共有フォルダ整理のルール

生成AIやAIを搭載したナレッジシステムを導入・検討する企業が急増していますが、システムを導入すれば、全てが解決されるわけではありません。
その性能を100%引き出すのは、データの品質です。
本書では、共有フォルダ整理ルールやナレッジシステム投入を意識した構造的課題とその解決策を解説しています。
文書の業務効率化リスク低減を目指す
7つの文書管理支援メニュー

文書管理の悩みを実践的な手法で解決するメニューを紹介しています。文書管理でどうしたらいいかわからない時はまずこちらを見てみましょう。
【必読】文書管理ルールのまるわかりガイドブック

もし文書管理ルールを見直すのであれば、是非この資料を見てみましょう。文書管理の必要性、課題、解決策などにについて解説した資料となっています。
記事カテゴリ一覧
会社情報


© Nichimy Corporation All Rights Reserved.